Quarteto de Anscombe
Quarteto de Anscombe são quatro conjuntos de dados que têm estatísticas descritivas quase idênticas (como a média e a variância), mas que têm distribuições muito diferentes e aparências muito distintas quando exibidos graficamente. Cada conjunto de dados consiste de onze pontos (x,y). Eles foram construídos em 1973 pelo estatístico Francis Anscombe, com o objetivo de demonstrar tanto a importância de se visualizar os dados antes de analisá-los, quanto o efeito dos outliers e outras observações influentes nas propriedades estatísticas. Ele descreveu o artigo como tendo a finalidade de combater a impressão entre os estatísticos de que "cálculos numéricos são exatos, mas gráficos são aproximados/grosseiros."[1]
Dados
Para os quatro conjunto de dados:
| Propriedade | Valor | Precisão |
|---|---|---|
| Média de x | 9 | exato |
| Variância de x | 11 | exato |
| Média de y | 7,50 | até 2 casas decimais |
| Variância de y | 4,125 | ±0,003 |
| Correlação entre x e y | 0,816 | até 3 casas decimais |
| Reta de regressão linear | até 2 e 3 casas decimais, respectivamente | |
| Coeficiente de determinação da regressão linear: | 0,67 | até 2 casas decimais |


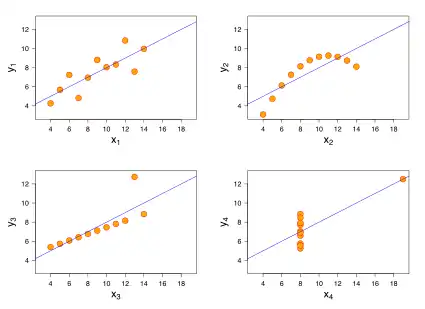
- O primeiro gráfico de dispersão (no canto superior esquerdo) aparenta ser uma simples relação linear, correspondendo a duas variáveis correlacionadas em que y poderia ser modelado como uma gaussiana com uma média linearmente dependente de x.
- O segundo gráfico (no canto superior direito) não mostra uma distribuição normal; enquanto a relação entre as duas variáveis é óbvia, ela não é linear, e o coeficiente de correlação de Pearson não é relevante. Uma regressão mais geral e o coeficiente de determinação correspondente seria mais apropriada.
- No terceiro gráfico (no canto inferior esquerdo), a distribuição é linear, mas deveria ter uma reta de regressão diferente (uma regressão robusta teria sido mais apropriada). A regressão calculada está deslocada por pelo único outlier que exerce influência suficiente para reduzir o coeficiente de correlação de 1 para 0.816.
- Finalmente, o quarto gráfico (no canto inferior direito) mostra um exemplo em que um ponto de grande alavanca é suficiente para produzir um grande coeficiente de correlação mas, embora outros pontos de dados não indiquem qualquer relação entre as variáveis.
O quarteto ainda é usado frequentemente para ilustrar a importância de visualizar um conjunto de dados graficamente antes de iniciar a análise de acordo com um tipo de relação particular, e a inadequação de propriedades estatísticas básicas para descrever conjuntos de dados realísticos.[2][3][4][5][6]
Os conjuntos de dados são os seguintes. Os valores de x são os mesmos para os três conjuntos de dados.[1]
| I | II | III | IV | ||||
|---|---|---|---|---|---|---|---|
| x | y | x | y | x | y | x | y |
| 10,0 | 8,04 | 10,0 | 9,14 | 10,0 | 7,46 | 8,0 | 6,58 |
| 8,0 | 6,95 | 8,0 | 8,14 | 8,0 | 6,77 | 8,0 | 5,76 |
| 13,0 | 7,58 | 13,0 | 8,74 | 13,0 | 12,74 | 8,0 | 7,71 |
| 9,0 | 8,81 | 9,0 | 8,77 | 9,0 | 7,11 | 8,0 | 8,84 |
| 11,0 | 8,33 | 11,0 | 9,26 | 11,0 | 7,81 | 8,0 | 8,47 |
| 14,0 | 9,96 | 14,0 | 8,10 | 14,0 | 8,84 | 8,0 | 7,04 |
| 6,0 | 7,24 | 6,0 | 6,13 | 6,0 | 6,08 | 8,0 | 5,25 |
| 4,0 | 4,26 | 4,0 | 3,10 | 4,0 | 5,39 | 19,0 | 12,50 |
| 12,0 | 10,84 | 12,0 | 9,13 | 12,0 | 8,15 | 8,0 | 5,56 |
| 7,0 | 4,82 | 7,0 | 7,26 | 7,0 | 6,42 | 8,0 | 7,91 |
| 5,0 | 5,68 | 5,0 | 4,74 | 5,0 | 5,73 | 8,0 | 6,89 |
Não se sabe como Anscombe criou seus conjuntos de dados.[7] Desde sua publicação, foram desenvolvidos vários métodos para produzir conjuntos de dados similares com estatísticas idênticas e gráficos distintos.[7][8]
Referências
- Anscombe, F. J. (1973). «Graphs in Statistical Analysis». American Statistician. 27 (1): 17–21. JSTOR 2682899. doi:10.1080/00031305.1973.10478966
- Elert, Glenn. «Linear Regression». The Physics Hypertextbook
- Janert, Philipp K. (2010). Data Analysis with Open Source Tools. [S.l.]: O'Reilly Media. pp. 65–66. ISBN 0-596-80235-8
- Chatterjee, Samprit; Hadi, Ali S. (2006). Regression Analysis by Example. [S.l.]: John Wiley and Sons. p. 91. ISBN 0-471-74696-7
- Saville, David J.; Wood, Graham R. (1991). Statistical Methods: The geometric approach. [S.l.]: Springer. p. 418. ISBN 0-387-97517-9
- Tufte, Edward R. (2001). The Visual Display of Quantitative Information 2nd ed. Cheshire, CT: Graphics Press. ISBN 0-9613921-4-2
- Chatterjee, Sangit; Firat, Aykut (2007). «Generating Data with Identical Statistics but Dissimilar Graphics: A follow up to the Anscombe dataset». The American Statistician. 61 (3): 248–254. JSTOR 27643902. doi:10.1198/000313007X220057
- Matejka, Justin; Fitzmaurice, George (2017). «Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing». Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems: 1290-1294. doi:10.1145/3025453.3025912